




In the age of large language models and multi-purpose agents, it’s tempting to leap straight to general purpose robotics. But the real world success stories from warehouse robots to surgical assistants are built on narrow, deep expertise.
The question is:
How do we train robots that master one task so well, they outperform even human operators consistently, safely, and economically?
In this blog, we’ll explore how generative simulations, physics rich environments, and adaptive curricula enable exactly that. We’ll delve into the technical underpinnings while making the concepts accessible across various levels.
What Defines an Expert Robot?
- Masters of one: Built for a specific task (e.g., pallet alignment, surgical insertion).
- Resilient: Able to recover from rare but critical edge cases.
- Efficient: Trained on millions of variations synthetically, rather than hundreds manually.
- Deployment-ready: Validated in controlled yet diverse simulations before real world launch.
The AuraSim Simulation Pipeline for Task Specialisation
1. Task Specification (NLP or Programmatic)
Users define the task using structured config or natural language. AuraSim converts this into a full 3D environment including object mesh retrieval, material simulation, lighting realism, and sensor noise injection.
2. Physics, Sensor & Network Fidelity
We use adaptive-fidelity simulation optimised for realism:
- Contact Physics: soft/rigid body dynamics
- Sensors: RGB-D, LiDAR, thermal, IMUs
- Dynamics: motor compliance, joint lag
- Network Latency: realistic delay, jitter, packet loss
- Lighting/Weather: glare, fog, shadows
3. Curriculum Based Task Training
We develop dynamic curricula that evolve over the course of training. Difficulty scales with agent performance. Example curriculum levels include varied speed, occlusion, and distractors.
4. Edge Case Injection (Stress Testing)
Simulated rare events include:
- Occluded or overlapping objects
- Nearly identical materials
- Sensor failures
- Network drops or control lag
5. Training Algorithms
AuraSim integrates with PPO, SAC, DDPG (RL), imitation learning, and curriculum learning. Hybrid RL+LLM setups are also supported for high-level planning.
Training Loop:
obs = sim.reset()
for step in range(T):
action = policy(obs)
obs, reward, done, info = sim.step(action)
policy.update(obs, reward)
6. Sim2Real Transfer
We achieve low sim2real transfer loss by combining:
- Domain randomization
- Empirical noise injection
- Calibration with real logs
Evaluation Metrics:
- Grasp Success Rate: 97.2% (sim) vs. 94.1% (real)
- Sort Accuracy: 98.7% (sim) vs. 95.9% (real)
- Avg Latency: 72.5ms (sim) vs. 78.4ms (real)
Case Study: Specialised Pallet Alignment Bot
Task: Align and dock pallets in narrow warehouse slots
Approach: 600+ pallet geometries, realistic network conditions, trained via PPO + imitation learning
Results: 41% higher success than generalist systems, 2cm error margin, 87% fewer incidents
Why Not Just Use Real-World Data?
- Real data is expensive and unsafe to collect at scale
- Edge cases are hard to reproduce
- Manual annotations are error-prone
- Simulations offer control, speed, and precision
AuraSim Architecture & Training Loop
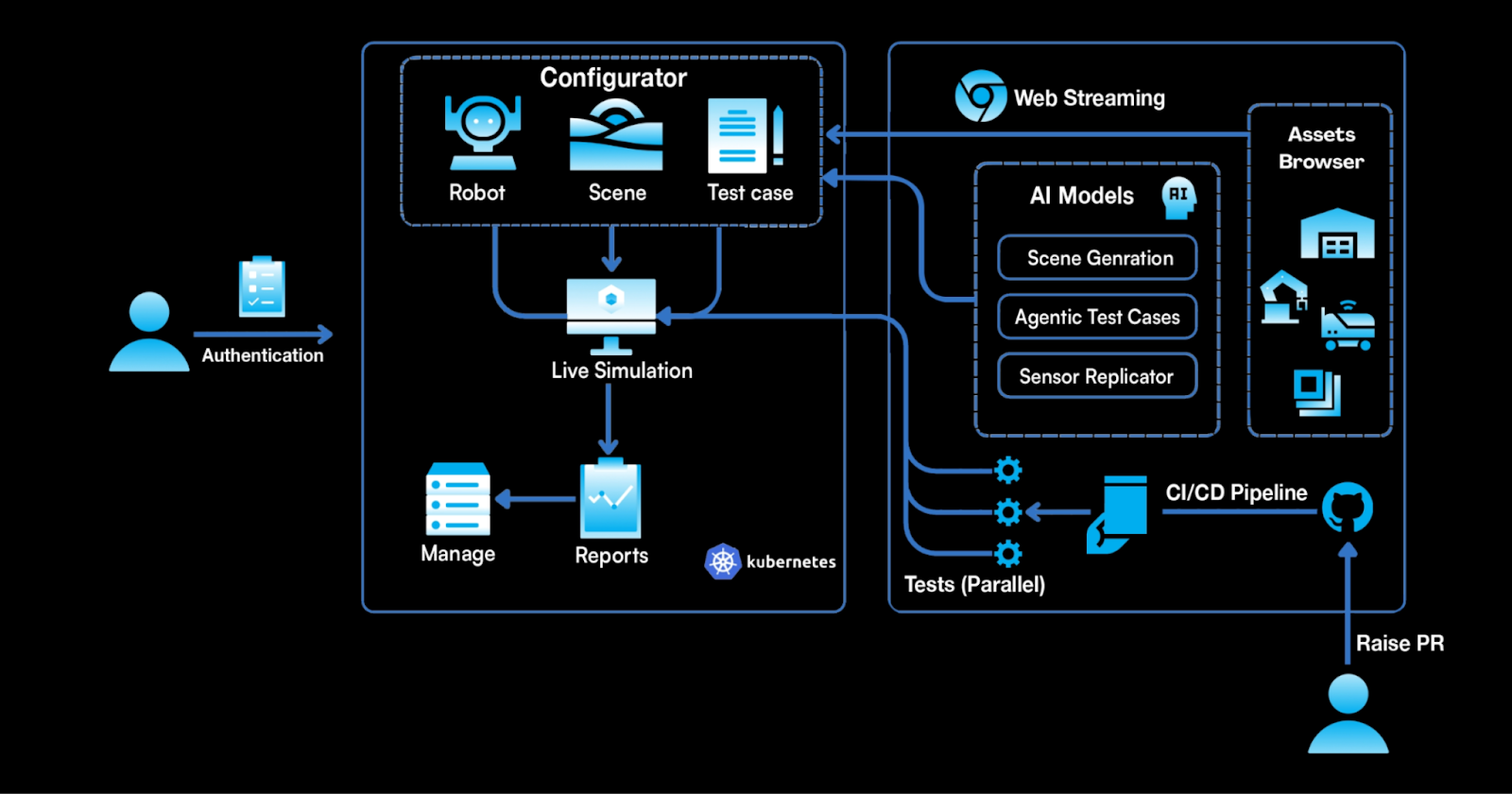
Conclusion: Mastery First, Generalization Next
Expert robots save time, cost, and lives. They serve as the foundation for general-purpose AI. AuraSim unifies generative AI, physics simulation, network realism, and task driven learning.
Are you building a robot that must excel at one thing better than any human ever could?
AuraSim is your simulation co-pilot.
Reach out: sarvagy.shah@auraml.com


Other Blogs You Might Be Interested In

.png)